📚 Executive Summary
- The Model: Human Judgment (Context) × AI Velocity (Scale) = Cognitive Throughput.
- The Myth: AI offers speed and consistency, but cannot replicate human stakes and contextual judgment.
- The Moat: Future value isn't in "using AI," but in architecting the systems that control it.
Open LinkedIn on any given day and you'll see some variation of: "AI will replace 40% of jobs by 2030" or "Learn to prompt or get left behind!" The subtext is always fear. Master this tool or else.
Here's the problem: that framing gets the relationship backwards.
AI doesn't replace humans. It augments them. Yes, AI will eliminate some roles and reshape many more—but the leveraged unit is still Human + AI, not AI alone. The correct mental model isn't "Human vs. AI" — it's Human + AI as a single operating unit. I call this the bionic layer.
Table of Contents
Part 1: The Bionic Operator Model
A bionic operator isn't just someone who uses ChatGPT to write emails faster. That's not augmentation; that's just autocompletion. Useful, but not transformative.
A bionic operator treats AI as extended cognition. The AI becomes:
- External memory: Patterns, decisions, and insights indexed and retrievable across months, not lost in forgotten Slack threads.
- Scenario generator: Multiple reasoning paths explored simultaneously, then synthesized.
- Calibration partner: A system that challenges assumptions and exposes blind spots — not a yes-machine.
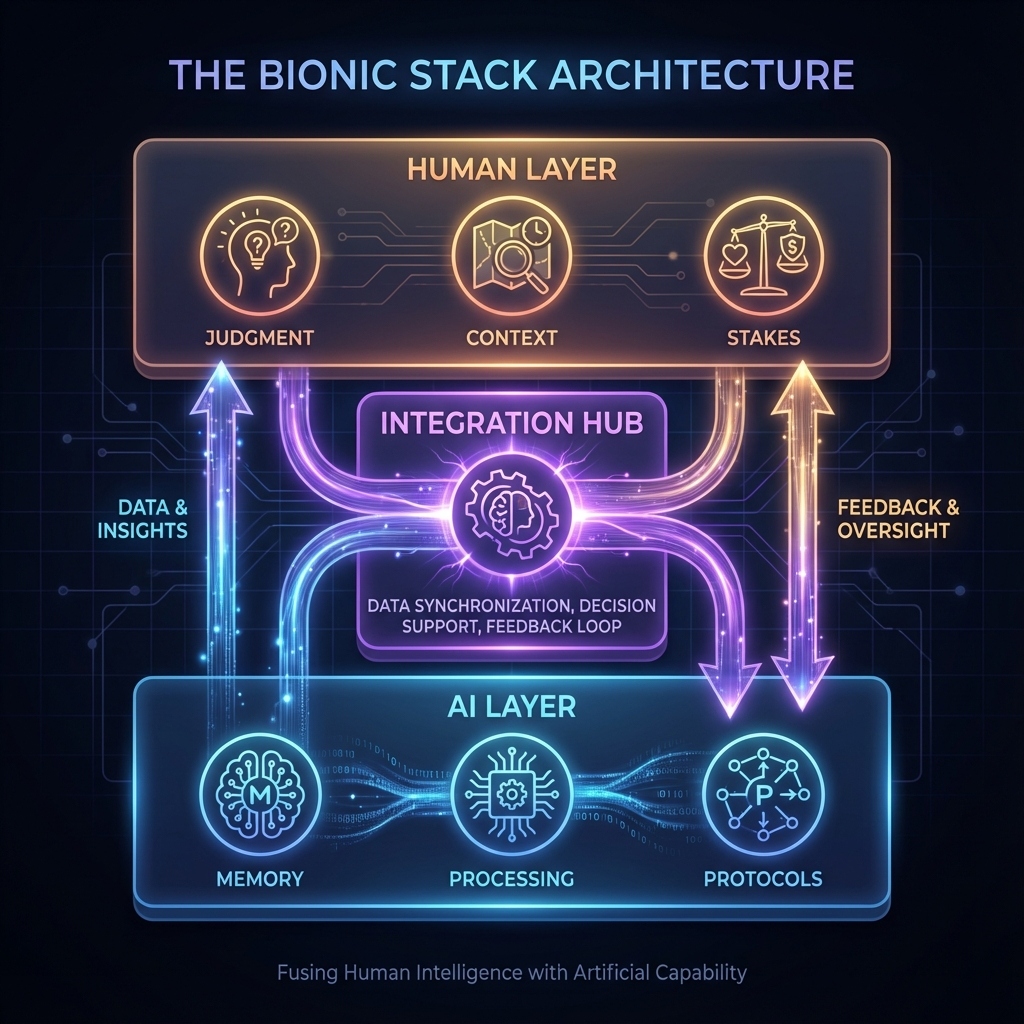
The goal isn't to outsource thinking. It's to upgrade thinking.
💡 Key Insight
Prompting matters, but it's table stakes. The compounding advantage comes from system design—building feedback loops between human judgment and machine capability.
Part 2: Why "Replacement" Thinking Fails
The replacement narrative assumes AI and humans are interchangeable. They're not. Here's where the domains actually differ:
| Capability | AI Strength | Human Strength |
|---|---|---|
| Pattern matching | Massive scale | Novel contexts |
| Speed | Instant generation | Knowing when to slow down |
| Consistency | No fatigue, no mood | Adaptive judgment |
| Stakes awareness | None (no skin in game) | Full (consequences are real) |
| Accountability | Cannot be held liable | Owns the decision |
An AI can generate 50 marketing headlines in 10 seconds. But it has no idea which one will resonate with your specific audience, or whether the timing is right, or whether the whole campaign is solving the wrong problem.
That's where the human layer remains irreplaceable — contextual judgment. (Though humans bring context and stakes—and also bias. That's why the feedback loop matters.)
Part 3: How I Built My Bionic Stack
This isn't theory. I run this model daily through a system I call Athena.
While I built Athena as a custom solution, you can achieve 80% of this without writing code—simply by maintaining a structured prompt library and logging your decisions in a shared doc. The architecture focuses on four pillars:
- Persistent Memory: Every conversation, decision, and insight gets indexed in a vector database (so the AI can retrieve relevant prior context, not just store notes). The AI "remembers" context from months ago.
- Protocol Library: A growing collection (230+ so far) of reusable frameworks for recurring problems—including decision memos, pre-mortem checklists, risk scoring rubrics, stakeholder maps, and term-sheet red flags.
- Session Logging: Each exchange gets checkpointed. If the AI hallucinates or I make a bad call, we can trace the reasoning chain.
- Challenge Mode: The AI is explicitly configured to push back on flawed premises, not just agree. A calibration partner, not a sycophant.
Part 4: The System in Action — A Real Example
Here's what this looks like in practice. A friend asked me to invest $25,000 as one of four "silent partners" in his hawker stall. Before Athena, I would have either spent weeks doing informal research or simply trusted my gut. Here's what happened instead:
📋 Case Study: BCM Hawker Stall Investment Analysis
- Input: A friend's pitch for a "silent partner" investment in a Bak Chor Mee stall. $100K total raise (4 partners × $25K each). No formal business plan. Verbal profit-sharing terms.
- Athena steps: Applied 7 frameworks (PESTLE, Five Forces, SWOT, TOWS, EV calculation, Funding Ladder, Term Sheet). Ran financial projections across 3 scenarios. Cross-validated with 4 other AI models to catch blind spots.
- Key discovery: For NEA-managed hawker centres, tenancy rules require stallholders to personally operate the stall—subletting means termination. My "equity" was actually an unsecured personal loan with zero legal protection.
- Output: 15-section due diligence report. Recommendation: DO NOT INVEST. Expected Value: −$18,181 per partner over 3 years. Probability of loss: 70%. (Assumptions: 40% Y1 failure rate, $0 downside recovery, 10% discount rate.)
- Human judgment: Decision was clear—but the deal structure made enforcement impossible even if the stall succeeded. The structured analysis made the "no" defensible.
- Measured gain: Traditional analyst time: 1–2 weeks, ~$5,000. Athena time: ~1 hour, ~$5 in API credits.
This is an example of my workflow, not financial advice.
The result? I operate at roughly 3–5x the cognitive throughput I had before. (By "cognitive throughput" I mean: time-to-decision, number of scenarios evaluated, and auditability per hour of work.) Not because the AI does my thinking for me, but because it handles the scaffolding while I focus on judgment calls.
Part 5: The Real Competitive Moat
Here's what most people miss:
In a world where everyone has access to AI, the differentiator isn't the AI. It's the quality of the human operating it.
A mediocre strategist with a frontier model is still a mediocre strategist. A sharp one becomes sharper. AI amplifies whatever you bring to the table—signal and noise alike.
The moat isn't "I know how to use AI." Everyone will, soon enough. The real moat is a ladder:
- Tools — Anyone can access these
- Workflows — Repeatable, documented processes
- Feedback loops — Error-correction and continuous learning
- Proprietary context — Your decisions, constraints, priors accumulated over time
- Taste & judgment — What to do and what not to do
Most people stop at level 1 or 2. The bionic operator builds to level 5.
Part 6: Limits & Risks (The Anti-Hype Section)
⚠️ What Could Go Wrong
To be honest about this model:
- AI increases throughput AND the risk of confidently wrong output. Speed without verification is just faster failure.
- Persistent memory creates privacy and security obligations. You're now managing a knowledge system with potentially sensitive data.
- If you don't log decisions, you don't have a system—you have vibes. The auditability is the whole point.
- This works best for "judgment-dense" work. If your job is pure execution with no ambiguity, the calculus is different.
The goal is "fewer unforced errors," not infinite content.
Part 7: The Bottom Line
Stop thinking about AI as a threat to prepare for. Start thinking about it as cognitive infrastructure you can install today.
The question isn't "Will AI take my job?"
The question is: "What could I build if I had 3x the mental bandwidth?"
More bandwidth isn't leisure—it's more reps, faster learning cycles, and better decisions under uncertainty.
That's the bionic opportunity. And it's already here.